TD5 : Tester l’existence d’un effet groupe
UP Mathématique appliquée
Objectifs de la séance
- Manipulation de données
- Grouper les données par modalité d’un facteur
- Effectuer des calculs par modalité du facteur
- Visualisation de données
- Boîte à moustaches
- Analyse de données
- Démarche statistique
- Reconnaître le contexte d’une analyse de la variance
- Ecrire le modèle correspondant
- Mettre en oeuvre le test du modèle complet
Exercices
Le problème qui suit est inspiré d’un stage de fin d’études réalisé par une étudiante de la spécialisation Science des données du cursus d’ingénieur agro-alimentaire d’Agrocampus.
Un groupe industriel commercialisant du café souhaite comparer les cafés provenant de différents lieux de production à partir de leur profil de composition physico-chimique, dont une des composantes importantes est le taux de matière sèche (DM). Pour cela, il s’appuie sur des données contenant le lieu de production, codé par un entier allant de 1 à 7, de 240 mesures de café disponible sur l’onglet Scripts et données de la page d’accueil du module.
Description des données sur la qualité du café
Importation des données
Importer le fichier de données
cafe_DM.csvdisponible sur la page des jeux de données dans un objet nommécafeen utilisant un scriptTD5_script.Rque vous aurez créé dans votre répertoire de projet.Quels sont les noms des variables de ce tableau de données ?
La nature de chacune de ces variables, telle que déclarée dans
R, correspond-elle à vos attentes ?Après cette transformation, la nature de chacune de ces variables correspond-elle finalement à vos attentes ?
Visualisation des données
- Construire la visualisation adaptée pour représenter les taux de matière sèche pour chaque site de production des cafés.
Calcul de statistiques descriptives
- Calculer les quartiles, le minimum, le maximum et l’écart-type pour chaque site de production.
Modélisation statistique
On cherche à répondre à la question suivante : Les taux de matière sèche moyens à l’échelle de toute la production diffèrent-ils d’un site à l’autre ?
Mise en place de l’analyse statistique
Donner l’expression du modèle statistique M\(_1\) permettant de répondre à cette question ? Quels sont les paramètres de ce modèle ?
Quelles sont les hypothèses H\(_{0}\) et H\(_{1}\) du test de l’existence de différences moyennes de taux de matière sèche entre les sites de production ? Exprimer ces hypothèses à partir des paramètres du modèle de la question précédente.
Donner l’expression mathématique du modèle sous l’hypothèse nulle H\(_0\).
Test de l’effet site de production sur la quantité de matière sèche
Quelle est la valeur estimée de l’écart-type résiduel du modèle M\(_{1}\) ?
Quelle est l’expression de la statistique de test permettant de tester l’existence de différences de moyennes entre les lieux de production ? Quelle est la valeur prise par cette statistique de test ?
Quelle est la distribution \(\mathcal{F}_{0}\) sous l’hypothèse H\(_{0}\) de la statistique de test \(F\) introduite à la question précédente ?
Répondre à la problématique
Analyse approfondie des résultats
Pour le site de production 3, rappeler le cadre du test de nullité du coefficient associé (hypothèses, interprétation des hypothèses, statistique de test, loi sous H\(_0\), décision)
Commenter le résultat de comparaison par paires des différents sites de production obtenu à l’aide de la fonction
meansComp
meansComp(res, ~Localisation)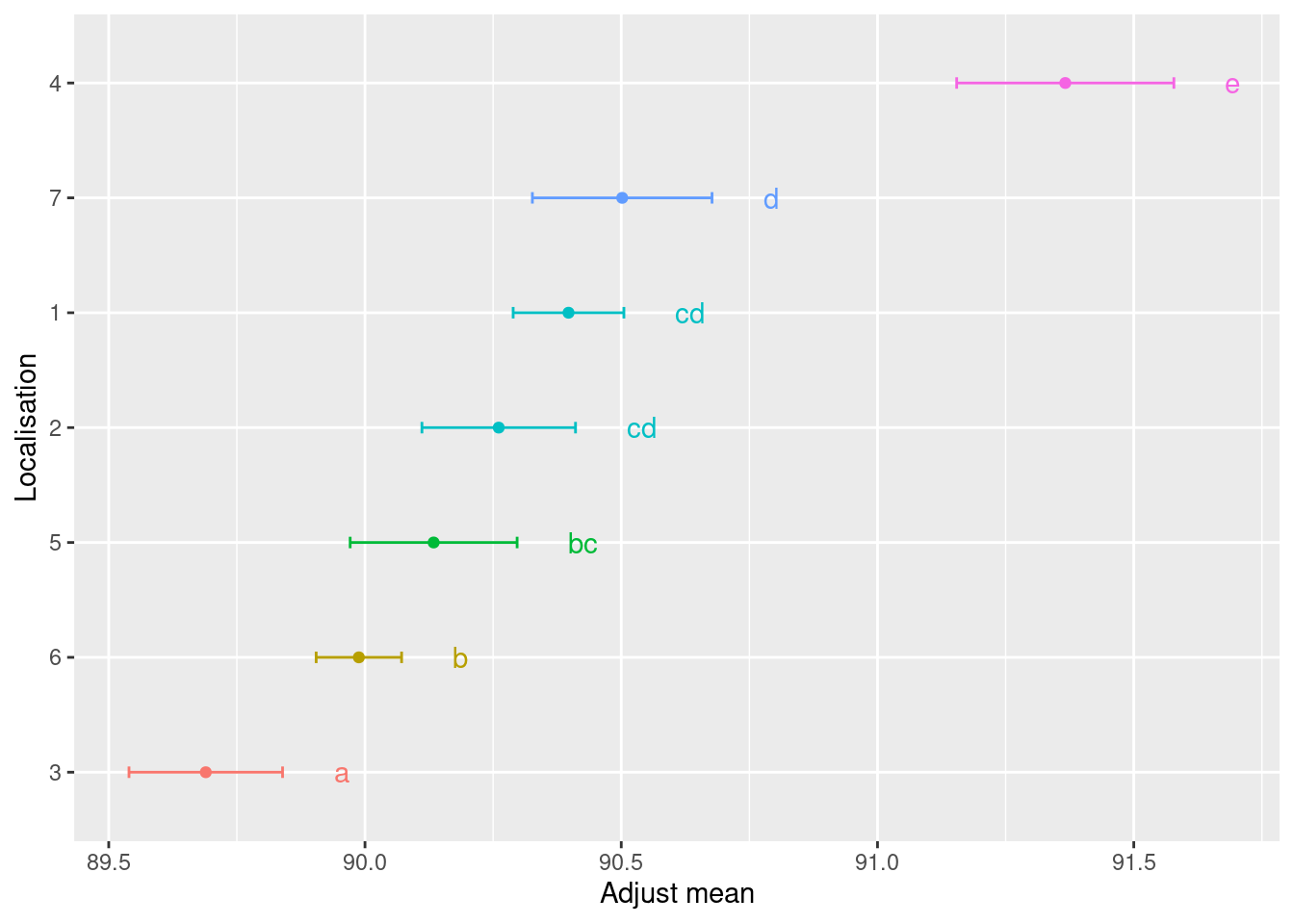
## $adjMean
## Localisation emmean SE df lower.CL upper.CL
## 1 90.40 0.05483 233 90.29 90.51
## 2 90.26 0.07604 233 90.11 90.41
## 3 89.69 0.07604 233 89.54 89.84
## 4 91.37 0.10754 233 91.15 91.58
## 5 90.13 0.08267 233 89.97 90.30
## 6 89.99 0.04231 233 89.90 90.07
## 7 90.50 0.08895 233 90.33 90.68
##
## Confidence level used: 0.95
##
## $groupComp
## 3 6 5 2 1 7 4
## "a" "b" "bc" "cd" "cd" "d" "e"
##
## attr(,"class")
## [1] "meansComp"Le vocabulaire de la séance
Commandes R
- as.factor
- group_by
- summarise
- LinearModel
- meansComp
Environnement R
Statistique
- Analyse de la variance
- Tests post-hoc